
Hi, I am an engineer and an organizer.
I did my bachelor's in Astronomy and Stats and a master's in Information Science from the University of Arizona. I had a stint as a Ph.D. student in Planetary Science which I left during my second year to finish schooling earlier and move closer to language models. Within AI, I am interested in data infrastructure, voice, and model behavior.
Currently, I am a Human Frontier Collective Specialist at Scale AI where I craft problems for frontier models and evaluate their problem-solving capacity. I am also building Nudge: a voice agent that autonomously calls and nudges you to tackle lingering tasks and habits. The common thread between the two has been prompting and context engineering. The models seem to have "a mind" of their own -- sometimes even the most insignificant-seeming phrase matters a lot!
Before pivoting, I did asteroid thermal modeling work for three and a half years as a research assistant for the PI of NASA's NEOS/NEOWISE mission. This role was a mix of data science and scientific programming. Turns out, if you have enough clean observations and a decent optimization algorithm constrained by some physics equations, you can figure out how large and ~bright space rocks are! Anyway, here, I published papers on the asteroid Apophis and also presented my research at conferences, including once, quite luckily and gratefully, at the United Nations.
I am also an avid community builder. I co-founded Tucson Effective Altruism (TEA), an organization aimed at introducing interested students to high-impact careers. For TEA, I am most proud of having developed and taught an applied philosophy course called PHIL 400/500: Pathways to Progress. Our alums have gone on to work on biosecurity and global health; one of them, for instance, started Access to Medicines Initiative, a non-profit that improves the contraceptive supply chain in Nigeria.
Browse through the tabs to learn more about my experiences so far, cheers!
Hi, I am an engineer and organizer.
I did my schooling at the University of Arizona. First, a bachelor's in astro and stats, followed by a stint as planetary science phd student, and then a master's in information science. I am currently a Human Frontier Collective Specialist at Scale, and I am building a voice-first agent app called nudge.
Before pivoting, I did asteroid thermal modeling work for three and a half years as a research assistant for the PI of NASA's NEOS/NEOWISE mission. I did standard academia things here: paper publication + conference posters and talks.
I am also an avid community builder. I co-founded Tucson Effective Altruism (TEA), an organization aimed at introducing interested students to high-impact careers. Here, I developed and taught an applied philosophy course called PHIL 400/500: Pathways to Progress.
Browse through the tabs to learn more about my experiences so far, cheers!
Nudge: Voice-First Collaborators

Nudge is now availabe on iOS' Testflight and on the Play Store's testing track. If you are intrigued by the idea and would like to be a beta tester, sign up here!
Can an autoregressive transformer learn how to solve the Knight's tour?
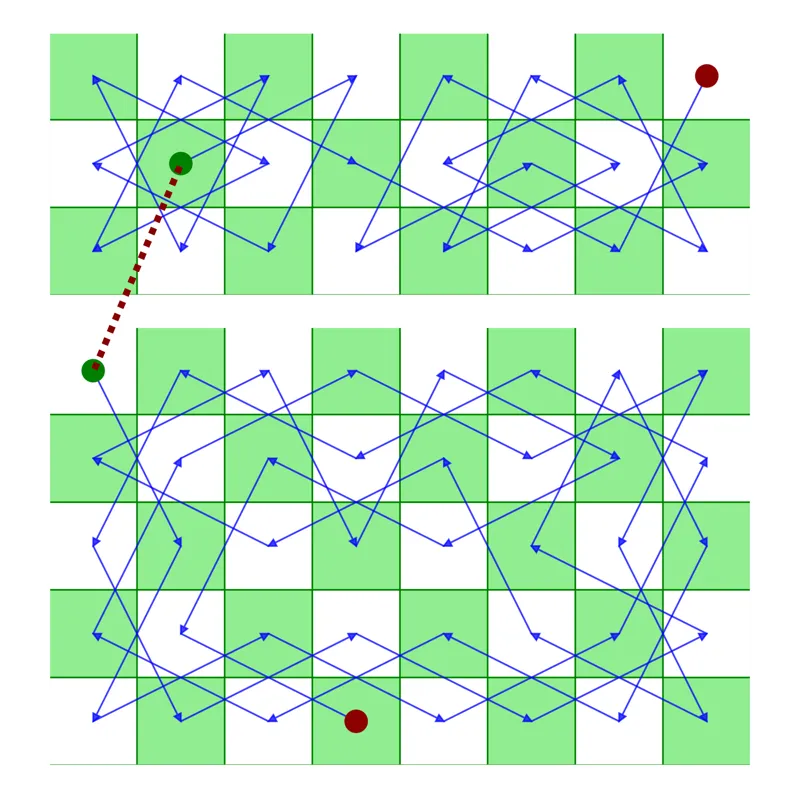
Code for generating the training examples, model set up, training, and evaluation can be found here: https://github.com/AsteroidHunter/knightsGPT
First, there are methodological debates and uncertainty surrounding the tests of generality. Second, generating out-of-distribution examples is difficult; the internet is vast, and it is hard to verify if evaluations with supposedly out-of-distribution examples are actually out-of-distribution. Third, even if truly novel, out-of-distribution examples can be crafted, interpretability methods are not advanced enough to determine whether the model solved the question using genuine reasoning or mere interpolation / pattern recognition.
Games and puzzles offer a unique opportunity to investigate generalization as they allow us to tightly constrain training and evaluation examples. Motivated by Li et al. (2022) and Ruoss et al. (2022), and after noticing that the Knight's tour had never previously been used as a test of generalization, I trained a GPT-2 variant on tens of millions of knight's tour puzzles encoded as linear indices and evaluated whether the model could solve unseen partial puzzles. I found that models are able to generalize, and the extent of generalization increases for models trained on more data. The version of the model trained on ~25 million Knight's tours could solve 999/1191 parberry puzzles.
A faithful replication of AlexNet
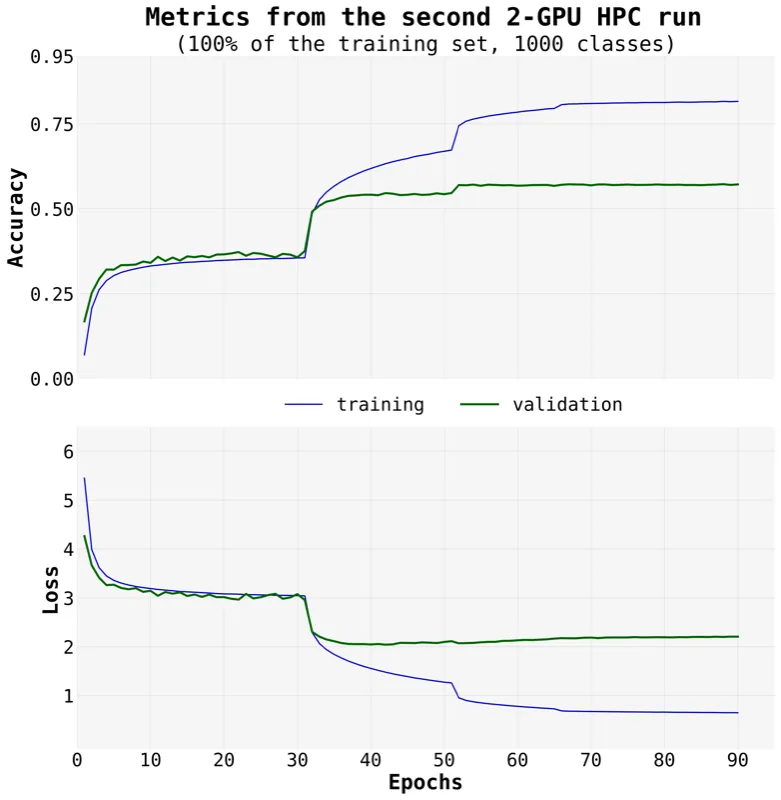
For this project, my goal was gaining more familiarity with research engineering practices in deep learning. I read the paper section-by-section and replicated everything the authors did in jupyter notebooks. I wanted the replication to be as faithful as possible, so I used the entire ~150 GB ImageNet 2010 dataset and the 2-GPU split architecture that the authors had used. While other alexnet replications exist, this is the first that employs model sharding the same way the authors originally did. My model's top-1 and top-5 accuracy were within 2.8% of the original paper.
The final code for the data augmentation, model training & evaluation, along with notes on challenges faced can be found here: https://github.com/AsteroidHunter/replicatingAlexNet
Building a local "high-performance" cluster

Besides helping with the build, I took charge of setting up the software for this mini computing cluster. I modeled the set up after University of Arizona's high-performance computers, which I had extensively used as an undergraduate and graduate research assistant. More concretely, this involved steps such as setting up duo and tailscale, installing CUDA drivers, and configuring SLURM for job scheduling. I continue being the "IT manager" of this machine, debugging it and resolving issues whenever remote workloads fail or the other user faces issues.
Size & Albedo distribution of Near-Earth Asteroids observed by NEOWISE
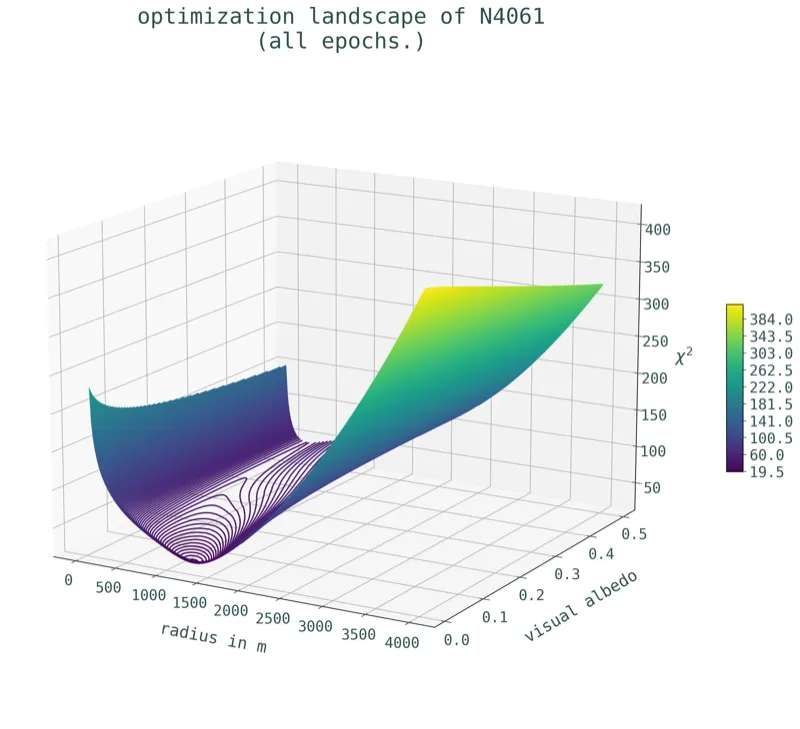
Graduate Research Assistant, NEOWISE/NEOS
2. Pipeline development & validation: I helped parallelize the thermal modeling pipeline using python's multiprocessing package. The other major task was validating the reliability of the pipeline, for which, I created a script that could generate synthetic asteroids using characteristics found in real-world observational data as the prior, and then tested if the results from the new pipeline were close to true diameters and albedos of the synthetic objects.
3. Characterization and analysis of 2200 NEAs: After the pipeline had been sufficiently developed and validated, I ran the algorithm on all the NEA observational data we had, inspected the validity of the fits (and re-fit bad fits using more appropriate parameters), and presented the final results in the form of a talk at the Planetary Defense Conference in Vienna.
Tucson Effective Altruism (TEA)

Co-founder & Organizer
- Spearheaded all core operations such as running weekly meetings, delegating tasks to a 10-person team, leading outreach initiatives, course logistics, and optimal management of a ~$3K annual budget
- Negotiated with the philosophy department leadership to convert our pilot 11-week discussion program into an accredited University of Arizona course, with 75+ participants over three years
- Drafted and improved the course's syllabus and readings, mediated weekly discussions, and managed teaching assistantship duties such as grading and office hours
- Amplified membership and awareness by delivering dozens of in-class pitches (with 100-600 attendees), hosting tabling events, and executing targeted email and social-media campaigns
- Doubled our Fall '24 & Spring '25 early-semester email list sign-ups from 75 to 160+ per semester through A/B-tested messaging and improved in-person outreach
- Leveraged Mailchimp, Qualtrics, Substack, CampusGroup's web-hosting platform, and D2L to automate email campaigns, process applications, disperse newsletters, and host course content
- Hosted catered symposia exploring topics within moral philosophy, AI safety, global health, career planning, and cause prioritization, attracting 25+ attendees
- Developed and iterated a writing-focused career development program, and offered 1-on-1 career guidance to students
- Conducted post-mortems and targeted interviews after each term to improve organizational efficiency and member satisfaction
Physical characterization of the potentially hazardous (99942) Apophis

Undergraduate Research Assistant, NEOWISE